Image by Author
# Introduction
There are numerous tools for processing datasets today. They all claim — of course they do — that they’re the best and the…
Introduction
Vision Language Models (VLMs) allow both text inputs and visual understanding. However, image resolution is crucial for VLM performance for processing text and chart-rich data. Increasing image resolution creates…
Earlier this year, we mentioned that we're bringing computer use capabilities to developers via the Gemini API. Today, we are releasing the Gemini 2.5 Computer Use model, our new specialized…
Micromobility solutions—such as delivery robots, mobility scooters, and electric wheelchairs—are rapidly transforming short-distance urban travel. Despite their growing popularity as flexible, eco-friendly transport alternatives, most micromobility devices still rely heavily…
Image by Author
# Introduction
You've been coding in Python for a while, absolutely love it, and can probably write decorators in your sleep. But there's this nagging…
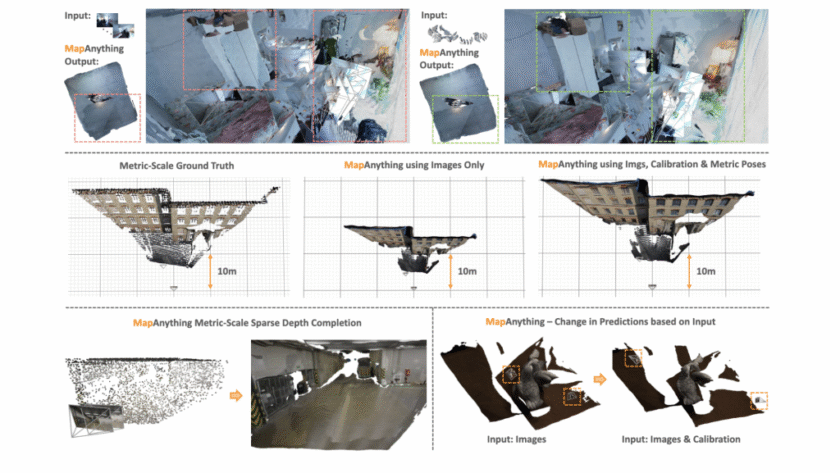
A team of researchers from Meta Reality Labs and Carnegie Mellon University has introduced MapAnything, an end-to-end transformer architecture that directly regresses factored metric 3D scene geometry from images and…
Estimated reading time: 5 minutes
Introduction
Embodied AI agents are increasingly being called upon to interpret complex, multimodal instructions and act robustly in dynamic environments. ThinkAct, presented…
Image by Editor
# Introduction
One of the most difficult pieces of machine learning is not creating the model itself, but evaluating its performance.
A model might…
IBM has released Granite-Docling-258M, an open-source (Apache-2.0) vision-language model designed specifically for end-to-end document conversion. The model targets layout-faithful extraction—tables, code, equations, lists, captions, and reading order—emitting a structured, machine-readable…